OpenGL Particle Systems
This article details the changes in memory structure, algorithms and shaders that contributed to a performance increase in the Sector's Edge particle system.

This is a continuation on the original article Particle Optimisations with OpenGL and Multithreading, which details the initial methods used in the particle system in our free to play first person shooter Sector's Edge.
This article details the changes in memory structure, algorithms and shaders that contributed to a performance increase in this particle system.
The source code for this particle system is available on GitHub.
Particle Storage Benchmarks
Particles were initially stored in multiple linked lists as it allowed particles to be added and removed quickly without worrying about array capacity. Based on feedback I received, I measured the time spent in ticks (10000 ticks = 1 millisecond) of adding new particles, accessing particle data and removing particles with different storage types.
Adding Particles
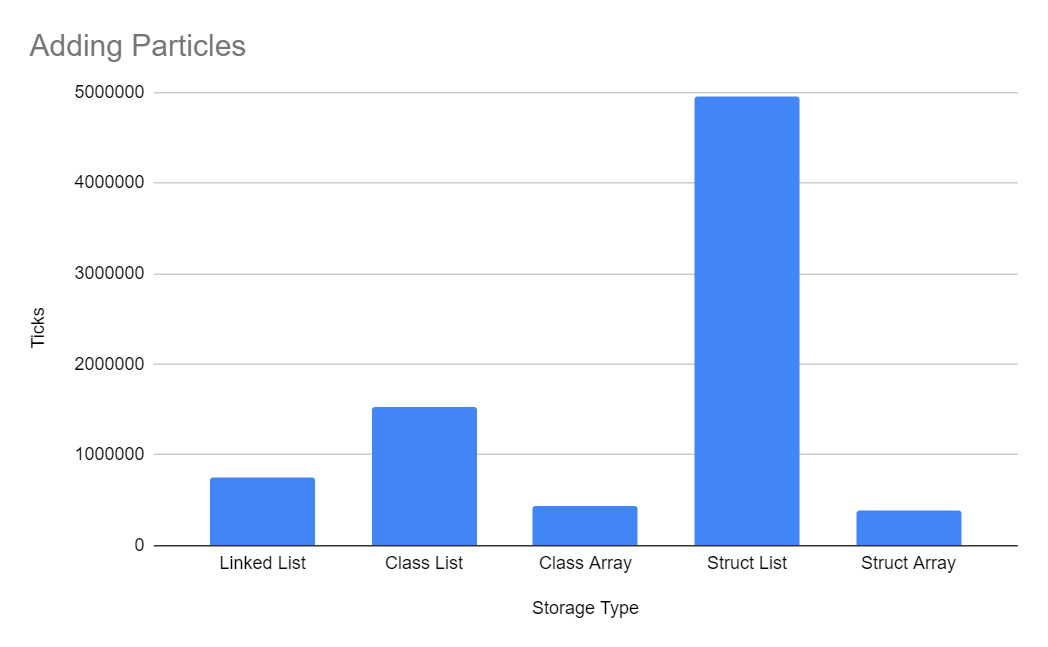
Class and Struct arrays were fastest here since they allow for particles to be pre-allocated and reset in-place, whereas Class and Struct lists were slower since they require allocating a new Particle instance each time.
In an attempt to improve the performance of adding to Class and Struct lists, I kept a separate list of 'disposed particles', which I would copy from rather than allocating a new particle each time. This increased the speed by about 2x, but as seen above it's still much slower than the other methods.
I believe adding to Class and Struct lists were slower than Linked List because of the function call overhead of List<T>.Add(...).
Accessing Particles
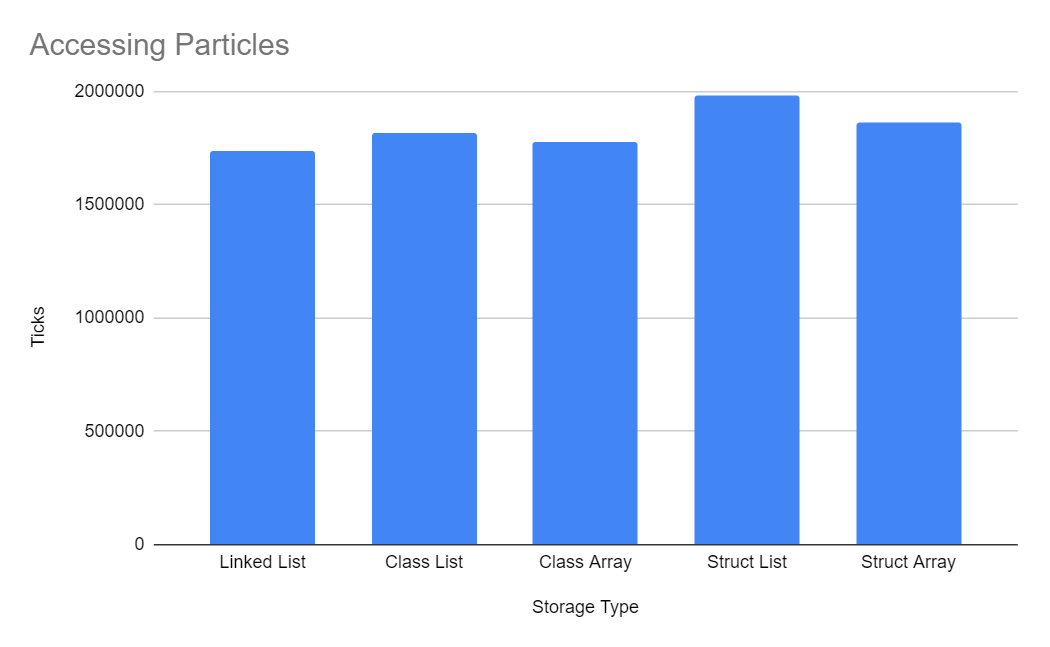
The above numbers were measured by accessing each particle in order, which allows for a realistic comparison between Linked Lists and the other methods. In Sector's Edge there isn't a use case for accessing a particle at an arbitrary index, so we don't need to benchmark random access.
Struct Arrays received a slight advantage since they can be accessed by reference with a fixed pointer, however Class List/Array were still slightly faster for reasons I'm unsure of.
Accessing Linked Lists was surprisingly the fastest, which I assume is because it requires no array bounds checks.
Removing Particles
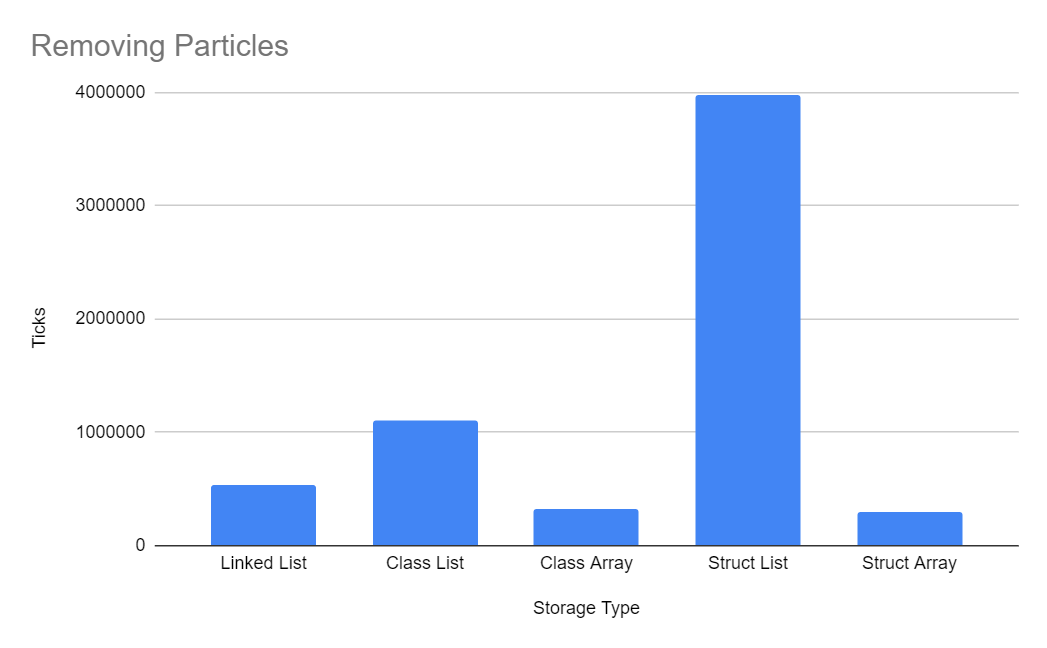
Elements were removed from classes and lists using the swap and pop method, where the nth element is replaced with the last element and the array size is reduced by one.
Removing from Class and Struct lists was the slowest because of the function call overhead of List<T>.RemoveAt(...). Removing from a Struct list was by far the slowest since C# does not allow accessing List elements by reference, meaning the struct gets copied around in memory more than the other storage types.
I was surprised that Linked List did not have the fastest remove operations, since it requires only one operation:
// Remove from the linked list
particle.Next = particle.Next.Next;
// Remove from the struct array
array[n] = array[--arrayLength];
// Remove from the struct list
int removeIndex = list.Count - 1;
list[i] = list[removeIndex];
list.RemoveAt(removeIndex);Class Array vs Struct Array
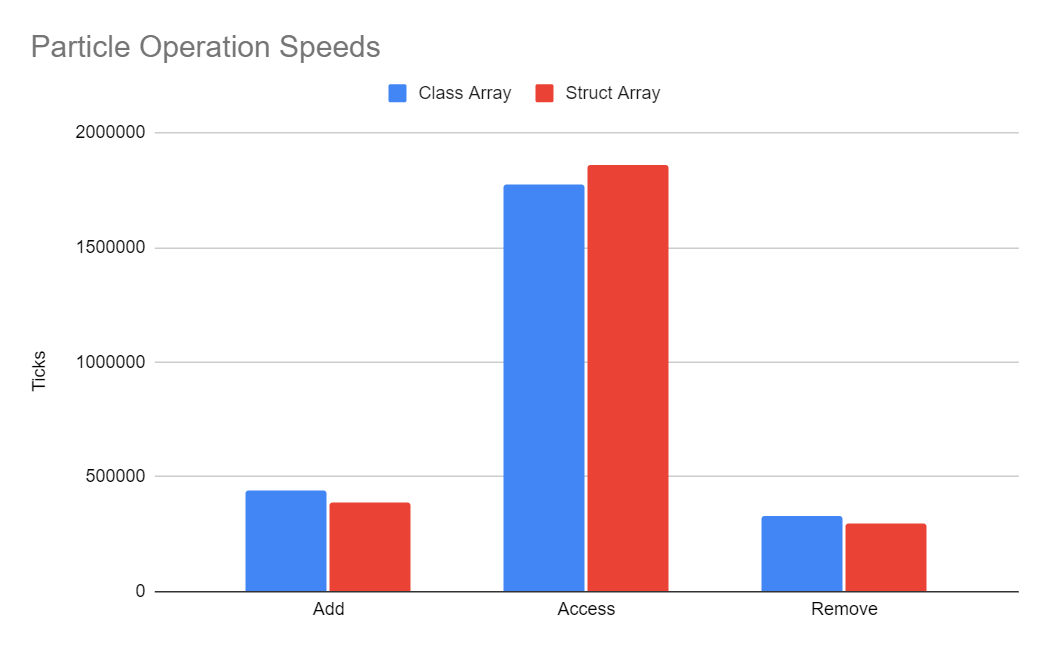
Based on the numbers below, I decided to switch to Struct Arrays since the access speed difference is negligible and Struct Arrays can be accessed with fixed pointers, which provides additional benefits in the Sector's Edge engine.
Struct Array Add is 13% faster
Class Array Access is 5% faster
Struct Array Remove is 10% faster
Particle Structure
Since structs are copied around a lot in memory, the size of a Particle needed to be trimmed down. The original Particle class was 152 bytes and had the following composition:
public class OldParticle
{
public Matrix4F transform; // Matrix4F = struct of 16 floats
public Vector3 position; // Vector3 = struct of 3 doubles
public Vector3 velocity;
public Vector3 rotation;
public float scale;
public uint colour;
public float lifeTime;
public Particle Next;
}
The new Particle struct is 60 bytes and copies ~2.5x faster than if it remained the same size:
public struct NewParticle
{
public Vector3F position; // Vector3F = 3 floats
public Vector3F velocity;
public Vector3F rotation;
public float scale;
public uint colour;
public int lifetime;
}
The transform variable was stored in the old particle system so that when the particle comes to rest, its transform no longer needed to be recalculated each frame. In the new particle system the percentage of a particle's lifetime where it is actually at rest is so small that it's no longer worth storing this variable in the Particle.
Previously the transform was updated in-place in the Particle and then copied to the mapped OpenGL buffer. In the new particle system we obtain a reference to the struct in shared GPU memory and write to it directly, saving the overhead of copying a Matrix4F struct:
// Obtain a direct reference to the Matrix4F struct in shared GPU memory
ref Matrix4F transform = ref mappedPtr[bufferOffset++];
// Update it directly
transform.M11 = ...
transform.M12 = ...All Vector3 structs were changed to Vector3F structs to reduce memory usage and all particle-related math was changed from double to float. Double and float operations like addition and multiplication are identical in speed and the reduced precision is not visible to the human eye in-game.
Batch Particle Adds
Previously, the particle system worked with N linked lists, where N is the amount of threads supported by the CPU. This allowed each thread to work separately with its own linked list (note that variables prefixed with t_ are accessed by multiple threads):
Particle[] t_LinkedLists = new Particle[THREAD_COUNT];
Due to the nature of Linked Lists, particles could only be added to one list at a time. With struct arrays, we can now add an entire batch of particles to an array at once.
The particle storage now looks like this:
ParticleStruct[][] t_Particles = new ParticleStruct[THREAD_COUNT][];
// This tracks how many particles have been added to each array
int[] t_ParticleCount = new int[THREAD_COUNT];
To add a new batch of particles, we must first check there is enough available space in the array:
protected void CheckParticleArraySize(ref Particle[] currentArray, int currentCount, int batchSize)
{
// Early exit if already at max size
if (currentCount == Constants.MaxParticlesPerThread)
return;
var currentCapacity = currentArray.Length;
// Calculate the total amount of particles after we add this batch
int newCount = currentCount + batchSize;
// If the current array can't hold that many particles
if (newCount >= currentCapacity)
{
// Either double the array size or increase it by 2048
var newLength = Math.Min(newCount + 2048, newCount * 2);
// There is no need to ever allocate more memory than the max amount of particles
newLength = Math.Min(newLength, Constants.MaxParticlesPerThread);
Array.Resize(ref currentArray, newLength);
}
}
The entire batch of particles is then added to one thread's particle storage:
void AddABatchOfParticles()
{
int batchSize = 6;
// Select which thread to add these particles to
var index = CurrentThreadAddIndex;
// Get references to that thread's particle storage
ref var currentArray = ref t_Particles[index];
ref var currentAmount = ref t_ParticleCount[index];
// Check we have enough room in the array to add this batch
CheckParticleArraySize(ref currentArray, currentAmount, batchSize);
// Add the particles
for (int i = 0; i < batchSize; i++)
AddParticle(ref currentArray, ref currentAmount, Vector3F.Zero, Vector3F.Zero, 0, 0, 0);
}
Adding Particles
The slowest part of the old AddParticle(...) function (source code) was that it had to move a Particle from the decayed particle list to the active particle list and then update it. If there were no decayed particles available, a new Particle had to be allocated.
The overhead of copying and allocating new Particles is avoided in the new particle system as it modifies existing memory using the Reset(...) function instead:
void AddParticle(ref Particle[] currentArray, ref int currentCount, in Vector3F position, in Vector3F velocity, in int lifetime, in float scaleMod, in uint colour)
{
// If the current array exceeds the max amount of particles allowed, replace a random particle
var index = currentCount > Constants.MaxParticles ? rand.Next(currentCount) : currentCount++;
currentArray[index].Reset(
position,
velocity,
lifetime,
scaleMod,
colour);
}The Reset function simply sets each variable in the struct, which was faster than allocating a new struct, i.e. currentArray[index] = new Particle(...)
public void Reset(Vector3F p, Vector3F v, int l, float s, uint c)
{
position = p;
velocity = v;
scale = s;
colour = c;
lifetime = l;
}
Updating Particles
After we update a particle (move it, rotate it, check collision with the map), we write its matrix transform directly to shared GPU memory with glMapBuffer. In the old system, this process was as follows:
- frame start
- map the particle buffer
- write to the buffer with multiple Tasks
- wait for all Tasks to finish
- unmap the buffer
- render the particles
- frame end
This meant that each frame there were two bottlenecks:
- waiting for all Tasks to finish
- waiting for the GPU driver to copy the new buffer data to the GPU before rendering
The new system avoids these bottlenecks with a slightly different process:
- frame start
- wait for all Tasks to finish*
- unmap the particle buffer*
- render the particles*
- orphan the buffer
- map the buffer
- write to the buffer with multiple Tasks
- frame end
Stages above that are marked with * do not occur on the very first frame since the particle buffer has not been written to yet.
There are two main differences with the new process:
- the particle buffer is orphaned before writing to it
- the Tasks can continue running once the frame ends, meaning it is likely that there will be little to no time spent waiting for the Tasks to finish when the next frame starts
The reason we orphan the particle buffer is to avoid sync points, which is where the CPU is waiting for the GPU to finish it's current work. This negatively impacts the performance of the game and should be avoided where possible.
A sync point can happen when the CPU attempts to modify a buffer immediately after requesting it to be rendered. An example of this is below, where the Gl.MapBuffer(...) call will wait until the above Gl.DrawArrays(...) function has been processed by the GPU before continuing:
Gl.BindBuffer(BufferTarget.ArrayBuffer, bufferHandle);
Gl.DrawArrays(PrimitiveType.TriangleStrip, 0, currentLength);
var ptr = Gl.MapBuffer(BufferTarget.ArrayBuffer, Gl.READ_WRITE); // SYNC POINT
// Write data to ptr...
Gl.UnmapBuffer(BufferTarget.ArrayBuffer);
Gl.BindBuffer(BufferTarget.ArrayBuffer, 0);
This sync point can be avoided with buffer orphaning, which is where calling Gl.BufferData after Gl.DrawArrays will tell the GPU driver to allocate a new region of memory for this buffer, while still retaining the old region of memory for the prior Gl.DrawArrays call.
We can now write to this new region of memory with Gl.MapBuffer(...) without creating a sync point. Both regions of memory are associated with this single buffer and once that Gl.DrawArrays call is processed by the GPU, the old region of memory is freed.
This is essentially double-buffering, but the GPU driver handles it for us.
The actual process of updating particles is the same as the old system, where the particle buffer is mapped and written to by multiple Tasks.
Trigonometry
The old particle system pre-calculated the sin wave and stored it in an array for faster lookup (source code).
At the time of writing this article, I decided to benchmark these systems again and it seems that optimisations in the .NET runtime mean that Math.Sin(...) is now the fastest method.
Here are the results of calculating 30 million sin and cos values:
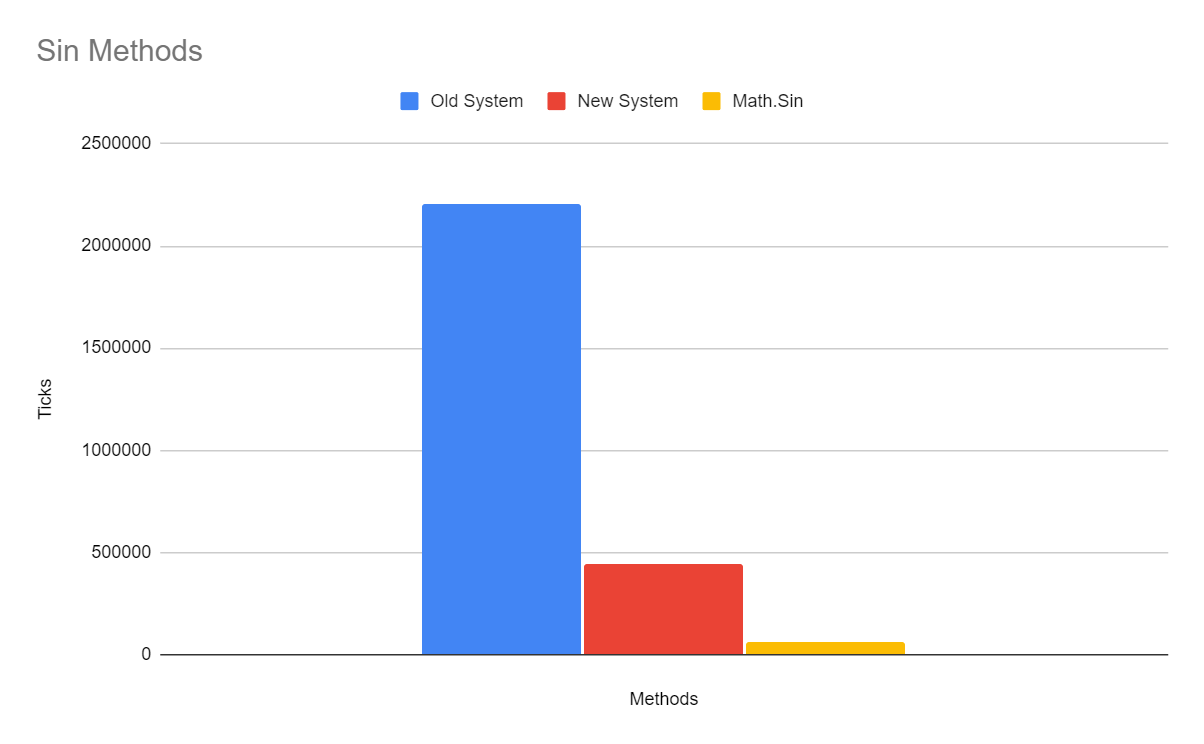
Based on these measurements I have switched back to using the base Math.Sin(...) and Math.Cos(...) functions.
Particle Matrix
The old particle system worked with traditional 4x4 matrices, however the values M13, M14, M24, M34 and M44 were never used:
public static Matrix4F OldParticleMatrix(in float scale, in float rotationX, in float rotationZ, in Vector3 position)
{
// Get the sin and cos values for the X and Z rotation amount
GetSinAndCosCheap(rotationX, out float sinX, out float cosX);
GetSinAndCosCheap(rotationZ, out float sinZ, out float cosZ);
Matrix4F m = Matrix4F.Identity;
m.M11 = scale * cosZ;
m.M12 = scale * sinZ;
m.M21 = -scale * cosX * sinZ;
m.M22 = scale * cosX * cosZ;
m.M23 = scale * sinX;
m.M31 = scale * sinX * sinZ;
m.M32 = -scale * sinX * cosZ;
m.M33 = scale * cosX;
m.M41 = (float)position.X;
m.M42 = (float)position.Y;
m.M43 = (float)position.Z;
return m;
}
The new particle system uses a custom 3x4 Matrix, which stores the same values but without the unused variables.
float a = p.renderScale;
float sX = (float)Math.Sin(p.rotation.X);
float cX = (float)Math.Cos(p.rotation.X);
float sZ = (float)Math.Sin(p.rotation.Z);
float cZ = (float)Math.Cos(p.rotation.Z);
float acZ = a * cZ;
float acX = a * cX;
float asX = a * sX;
// Custom Matrix3x4 that uses less operations in the vertex shader
transform.M11 = acZ;
transform.M12 = -a * sZ;
transform.M13 = acX * sZ;
transform.M14 = acX * cZ;
transform.M21 = -asX;
transform.M22 = asX * sZ;
transform.M23 = acZ * sX;
transform.M24 = acX;
transform.M31 = p.position.X;
transform.M32 = p.position.Y;
transform.M33 = p.position.Z;
I then wrote the full Scale * RotationX * RotationZ * Translation * MVP matrix out on paper and asked my mathematician brother to simplify it down and remove any unnecessary additions and multiplications. This produced the following behemoth in the vertex shader, which improved the frames-per-second of rendering 50,000 particles from the low 130's to the high 140's on my laptop:
uniform mat4 mvp;
layout (location = 0) in vec4 aPosition;
layout (location = 1) in vec4 aColour;
layout (location = 2) in mat4 aTransform;
flat out vec4 colour;
void main()
{
vec4 a0 = aTransform[0];
vec4 a1 = aTransform[1];
vec4 a2 = aTransform[2];
vec4 b0 = mvp[0];
vec4 b1 = mvp[1];
vec4 b2 = mvp[2];
vec4 b3 = mvp[3];
vec3 v = aPosition.xyz;
gl_Position = vec4((a0.x * b0.x) * v.x + (a0.z * b0.x + a0.w * b1.x + a1.x * b2.x) * v.y + (a1.y * b0.x + a1.w * b2.x) * v.z + (a2.x * b0.x + a2.z * b2.x + b3.x),
(a0.x * b0.y + a0.y * b1.y) * v.x + (a0.z * b0.y + a0.w * b1.y + a1.x * b2.y) * v.y + (a1.y * b0.y + a1.z * b1.y + a1.w * b2.y) * v.z + (a2.x * b0.y + a2.y * b1.y + a2.z * b2.y + b3.y),
(a0.x * b0.z + a0.y * b1.z) * v.x + (a0.z * b0.z + a0.w * b1.z + a1.x * b2.z) * v.y + (a1.y * b0.z + a1.z * b1.z + a1.w * b2.z) * v.z + (a2.x * b0.z + a2.y * b1.z + a2.z * b2.z + b3.z),
(a0.x * b0.w + a0.y * b1.w) * v.x + (a0.z * b0.w + a0.w * b1.w + a1.x * b2.w) * v.y + (a1.y * b0.w + a1.z * b1.w + a1.w * b2.w) * v.z + (a2.x * b0.w + a2.y * b1.w + a2.z * b2.w + b3.w));
colour = aColour;
}
Particle Model
The old system used a particle cube model with 36 vertices (2 triangles on each face) which was rendered with GL_TRIANGLES.
The new system uses a cube model composed of 14 vertices rendered with GL_TRIANGLE_STRIP, which renders ~2x faster on the GPU than previously. However since each side of the cube now shares two vertices with another side, the normal values are interpolated incorrectly across multiple faces.
This was solved by using the flat out and flat in qualifiers in the vertex and fragment shaders and adjusting the order of normals in the triangle strip so that the provoking vertex is aligned correctly with each face of the cube.
When using flat-shading on output variables, only outputs from the provoking vertex are used; every fragment generated by that primitive gets its input from the output of the provoking vertex - Khronos
Conclusion
With the optimisations detailed in the above sections, the new particle system benefits from:
- reduced memory usage due to smaller structs and vertices
- faster particle creation with batch additions
- faster particle deletion with swap and pop
- faster rendering on the GPU due to less vertices, faster matrix operations
- less time waiting for Tasks to finish
- no OpenGL sync points
You can see the particle system in action in the launch trailer for Sector's Edge, which has now released free to play on Steam!