Voxel World Optimisations
This article details the voxel mesh generation technique used in our game Sector's Edge.

Sector's Edge is a first person shooter that takes place in a voxel environment, where the world is composed of millions of destructible cubes. With 16 players per match, the mesh must be regenerated nearly every frame. This is a CPU-intensive process and this article dives into the optimisations that make it possible.
Our two goals for this engine are:
- fast mesh regeneration balanced with low triangle count
- fast vertex processing on the GPU
The second topic will be available in a separate article soon.
The full source code for this article is available here on GitHub.
Update: a new article has been posted that describes the further optimisations made to reduce chunk mesh initialisation time down to 0.48ms.
Map Structure
The map is divided into chunks of 32 x 32 x 32 blocks. Each chunk has its own mesh - a list of triangles - which must be regenerated each time a block is added, removed or damaged. Block data is stored in the following structure:
public class Map
{
Chunk[,,] chunks;
}
public class Chunk
{
const int CHUNK_SIZE = 32;
const int CHUNK_SIZE_SQUARED = 1024;
const int CHUNK_SIZE_CUBED = 32768;
Block[] data = new Block[CHUNK_SIZE_CUBED];
}
public struct Block
{
byte kind; // Block type, e.g. empty, dirt, metal, etc.
byte health;
}
Greedy meshing is a popular algorithm for producing a mesh with a low triangle count, however it requires many block comparisons and in our case wasn't regenerating chunks fast enough. In our approach, blocks are combined into runs along the X and Y axis:

To reduce triangle count, a run will not be split if it is covered by a block. Runs are only split if the next block has a different texture or is damaged:
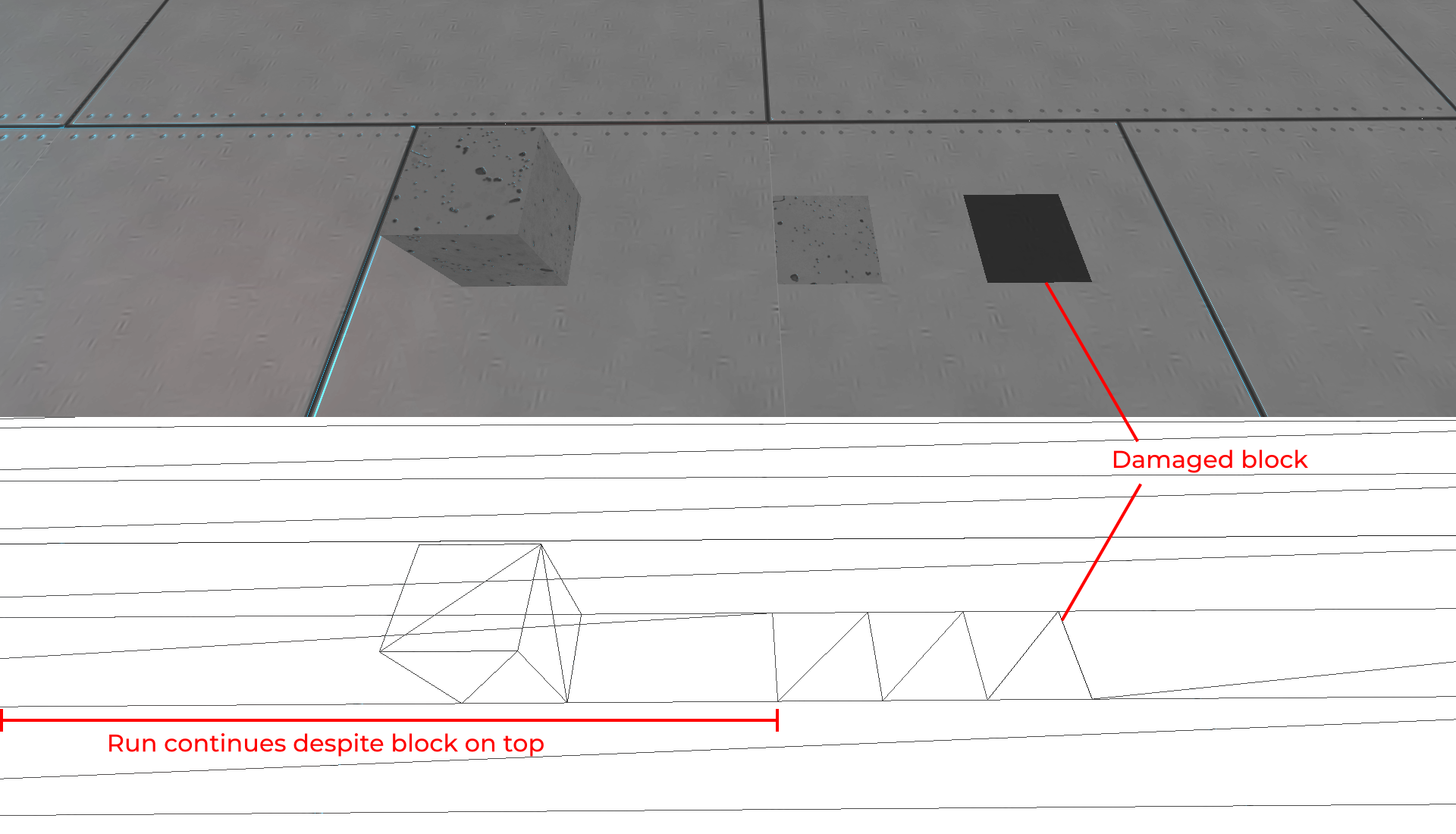
This allows chunk meshes to be regenerated with less block comparisons while still combining faces to reduce the triangle count.
Mesh Generation
The full Chunk class has the following structure:
public class Chunk
{
const int CHUNK_SIZE = 32;
const int CHUNK_SIZE_SQUARED = 1024;
const int CHUNK_SIZE_CUBED = 32768;
const int EMPTY = 0;
Block[,,] data = new Block[CHUNK_SIZE_CUBED];
// Global map position of this chunk
public int chunkX, chunkY, chunkZ;
// Each chunk has a reference to the map it is located in, so it can access
// blocks in other chunks
Map map;
// Stores vertex data and manages buffering to the GPU
BlockVertexBuffer vertexBuffer;
// References to neighbouring chunks
Chunk cXN, cXP, cYN, cYP, cZN, cZP;
public Chunk(int i, int j, int k, Map map)
{
chunkX = i * CHUNK_SIZE;
chunkY = j * CHUNK_SIZE;
chunkZ = k * CHUNK_SIZE;
this.map = map;
}
public void GenerateMesh(...) ...
void CreateRuns(...) ...
}
For clarity, i, j and k refer to chunk-relative positions (range 0-31)
and x, y and z refer to global map positions (range 0-511)
To start, GenerateMesh gets references to chunk neighbours for quick edge-case block comparisons. It then iterates over each block in the chunk and creates runs.
public void GenerateMesh(ChunkHelper chunkHelper)
{
// X- neighbouring chunk
cXN = chunkPosX > 0 ? m.chunks[chunkPosX - 1, chunkPosY, chunkPosZ] : null;
// X+ neighbouring chunk
cXP = chunkPosX < Constants.ChunkXAmount - 1 ? m.chunks[chunkPosX + 1, chunkPosY, chunkPosZ] : null;
// Y- neighbouring chunk
cYN = chunkPosY > 0 ? m.chunks[chunkPosX, chunkPosY - 1, chunkPosZ] : null;
// Y+ neighbouring chunk
cYP = chunkPosY < Constants.ChunkYAmount - 1 ? m.chunks[chunkPosX, chunkPosY + 1, chunkPosZ] : null;
// Z- neighbouring chunk
cZN = chunkPosZ > 0 ? m.chunks[chunkPosX, chunkPosY, chunkPosZ - 1] : null;
// Z+ neighbouring chunk
cZP = chunkPosZ < Constants.ChunkZAmount - 1 ? m.chunks[chunkPosX, chunkPosY, chunkPosZ + 1] : null;
int access;
// Y axis - start from the bottom and search up
for (int j = 0; j < CHUNK_SIZE; j++)
{
// Z axis
for (int k = 0; k < CHUNK_SIZE; k++)
{
// X axis
for (int i = 0; i < CHUNK_SIZE; i++)
{
access = i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED;
ref Block b = ref data[access];
if (b.kind == EMPTY)
continue;
CreateRun(ref b, i, j, k, chunkHelper, access);
}
// Extend the array if it is nearly full
if (vertexBuffer.used > vertexBuffer.data.Length - 2048)
vertexBuffer.Extend(2048);
}
}
}
The ChunkHelper class is used to record which faces have been merged, to prevent creating duplicate faces. Each chunk mesh is regenerated on a different thread and one ChunkHelper instance is allocated to each thread.
public class ChunkHelper
{
public bool[] visitedXN = new bool[CHUNK_SIZE_CUBED];
public bool[] visitedXP = new bool[CHUNK_SIZE_CUBED];
public bool[] visitedZN = new bool[CHUNK_SIZE_CUBED];
public bool[] visitedZP = new bool[CHUNK_SIZE_CUBED];
public bool[] visitedYN = new bool[CHUNK_SIZE_CUBED];
public bool[] visitedYP = new bool[CHUNK_SIZE_CUBED];
}
Separate runs are created for each block face orientation (X-, X+, Z-, Z+, Y-, Y+). For each block in the combined face, a flag is set in the respective array in ChunkHelper to indicate it has been merged.
void CreateRun(ref Block b, int i, int j, int k, ChunkHelper chunkHelper, int access)
{
// Precalculate variables
int i1 = i + 1;
int j1 = j + 1;
int k1 = k + 1;
byte health16 = (byte)(b.health / 16);
int length = 0;
int chunkAccess = 0;
// Left face (X-)
if (!chunkHelper.visitedXN[access] && VisibleFaceXN(i - 1, j, k))
{
// Search upwards to determine run length
for (int q = j; q < CHUNK_SIZE; q++)
{
// Pre-calculate the array lookup as it is used twice
chunkAccess = i + q * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED;
// If we reach a different block or an empty block, end the run
if (DifferentBlock(chunkAccess, b))
break;
// Store that we have visited this block
chunkHelper.visitedXN[chunkAccess] = true;
length++;
}
if (length > 0)
{
// Create a quad and write it directly to the buffer
BlockVertex.AppendQuad(buffer, new Int3(i, length + j, k1),
new Int3(i, length + j, k),
new Int3(i, j, k1),
new Int3(i, j, k),
(byte)FaceType.xn, b.kind, health16);
buffer.used += 6;
}
}
// Same algorithm for right (X+)
if (!chunkHelper.visitedXP[access] && VisibleFaceXP(i1, j, k))
{
...
}
// Same algorithm for back (Z-)
...
// Same algorithm for front (Z+)
...
// Same algorithm for bottom (Y-)
...
// Same algorithm for top (Y+)
...
}
The VisibleFace functions are used to check whether or not a block is empty. Most comparisons are within the working chunk, so we prioritise accessing block data directly within the chunk if possible.
bool VisibleFaceXN(int i, int j, int k)
{
// Access directly from a neighbouring chunk
if (i < 0)
{
if (cXN == null)
return true;
return cXN.data[31 + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
return data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
bool VisibleFaceXP(int i, int j, int k)
{
if (i >= CHUNK_SIZE)
{
if (cXP == null)
return true;
return cXP.data[0 + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
return data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
DifferentBlock is used to determine whether a block is different to the current run. Runs do not span across multiple chunks and therefore we do not need bounds checks when accessing the block.
protected bool DifferentBlock(int access, Block current)
{
// Using a ref variable here increased performance by ~4%
ref var b = ref data[access];
return b.kind != current.kind || b.health != current.health;
}
The AppendQuad function creates 6 vertices (two triangles) and writes them directly to the vertex buffer.
public static byte[] blockToTexture;
public static void AppendQuad(BlockVertexBuffer buffer, Int3 tl, Int3 tr, Int3 bl,
Int3 br, byte normal, byte kind, byte health)
{
// Each block kind maps to a texture unit on the GPU
byte texture = blockToTexture[kind];
// Each vertex is packed into one uint to reduce GPU memory overhead
// 18 bits for position XYZ
// 5 bits for texture unit
// 4 bits for health
// 3 bits for normal
// Each vertex in a quad shares the same texture unit, health and normal value
uint shared = (uint)((texture & 31) << 18 |
(health & 15) << 23 |
(normal & 7) << 27);
// Top left vertex
uint tlv = CombinePosition(tl, shared);
// Top right vertex
uint trv = CombinePosition(tr, shared);
// Bottom left vertex
uint blv = CombinePosition(bl, shared);
// Bottom right vertex
uint brv = CombinePosition(br, shared);
// Store each vertex directly into the buffer
buffer.data[buffer.used] = tlv;
buffer.data[buffer.used + 1] = blv;
buffer.data[buffer.used + 2] = trv;
buffer.data[buffer.used + 3] = trv;
buffer.data[buffer.used + 4] = blv;
buffer.data[buffer.used + 5] = brv;
}
// Combine position data with the shared uint
static uint CombinePosition(Int3 pos, uint shared)
{
return (uint)(shared |
((uint)pos.X & 63) |
((uint)pos.Y & 63) << 6 |
((uint)pos.Z & 63) << 12);
}Benchmarking
To test our optimisations, the same map was initialised three times in a row and the time taken to run GenerateMesh for each chunk was recorded. This was done single-threaded to ensure we were only measuring our function, not task scheduling.
Our initial benchmark was:807 chunks initialised in 4158ms1 chunk initialised in 5.15ms (average)
After optimisations: 807 chunks initialised in 722ms1 chunk initialised in 0.89ms (average)
How this 5.7x increase in speed was achieved is outlined below.
Update: a new article has been posted that describes the further optimisations made to reduce chunk mesh initialisation time down to 0.48ms.
Optimisations
Inlining (3% speed increase)
Apart from GenerateMesh, every method is inlined using this MethodImpl attribute:
using [MethodImpl(MethodImplOptions.AggressiveInlining)]
void CreateStrips(...) ...
Pre-Calculating and Ref Locals (5% speed increase)
Every multiplication, addition and memory lookup affects performance, so we pre-calculate the common operations.
For example at the start of the CreateRun function:
protected void CreateStrips(Block b, int i, int j, int k, ChunkHelper chunkHelper, int access)
{
int i1 = i + 1;
int j1 = j + 1;
int k1 = k + 1;
byte health16 = (byte)(b.health / 16);
...
}
In the BlockVertex class, we reduced 24 bitwise operations down to 19:
// Old - 24 bitwise operations per quad
static uint toInt(Int3 pos, byte texID, byte health, byte normal)
{
return (uint)((pos.X & 63) |
(pos.Y & 63) << 6 |
(pos.Z & 63) << 12 |
(texID & 31) << 18 |
(health & 15) << 23 |
(normal & 7) << 27);
}
// New - 19 bitwise operations per quad
public static void AppendQuad(...)
{
var shared = (uint)((t & 31) << 18 |
(health & 15) << 23 |
(normal & 7) << 27);
uint tlv = CombinePosition(tl, shared);
uint trv = CombinePosition(tr, shared);
uint blv = CombinePosition(bl, shared);
uint brv = CombinePosition(br, shared);
...
}
static uint CombinePosition(Int3 pos, uint shared)
{
return (uint)(shared |
((uint)pos.X & 63) |
((uint)pos.Y & 63) << 6 |
((uint)pos.Z & 63) << 12);
}
Ref locals are used where possible to avoid copying structs onto the stack and avoid multiple array lookups:
protected bool DifferentBlock(int i, int j, int k, Block compare)
{
ref var b = ref data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED];
return b.kind != compare.kind || b.health != compare.health;
}
Neighbouring Chunks (10% speed increase)
By storing references to neighbouring chunks at the start of GenerateMesh, we saved 32*32 expensive Map.IsNoBlock functions calls on each side of the chunk.
// Old
bool VisibleFace(int i, int j, int k)
{
// Access from global map coordinates
if (i < 0 || j < 0 || k < 0 ||
i >= CHUNK_SIZE || j >= CHUNK_SIZE || k >= CHUNK_SIZE)
{
return m.IsNoBlock(i + chunkPosX, j + chunkPosY, k + chunkPos.Z);
}
return data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
// New
bool VisibleFaceXN(int i, int j, int k)
{
// Access directly from neighbouring chunk
if (i < 0)
{
if (cXN == null)
return true;
return cXN.data[31 + j * Constants.ChunkSize + k * Constants.ChunkSizeSquared].kind == EMPTY;
}
return data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
// Same for VisibleFaceXP, VisibleFaceZN, ...
...
Single-Dimensional Arrays (20% speed increase)
Changing the block data array in the Chunk class from a multi-dimensional array to a single-dimensional array provided a noticeable improvement in performance:
// Old
Block[,,] data;
Block b = data[i,j,k];
// New
Block[] data;
Block b = data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED];
The same was done with the ChunkHelper arrays:
// Old
bool[,,] visitedXN = new bool[CHUNK_SIZE, CHUNK_SIZE, CHUNK_SIZE];
bool b = visitedXN[i,j,k];
// New
bool[] visitedXN = new bool[CHUNK_SIZE_CUBED];
bool b = visitedXN[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED];
This performance increase came from the fact that CHUNK_SIZE is a multiple of 2, and therefore the C# compiler could simplify the multiplications to bitshifts:
// Old
data[i, j, k];
// Underlying array access produced by the compiler
data[i + j * data.GetLength(0) + j * data.GetLength(0) * data.GetLength(1)];
// New
data[i + j * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED];
// Simplified array access produced by the compiler
data[i + j << 5 + k << 10];At times, we are also able to pre-calculate the single-dimensional array lookup, as seen in the CreateRun function:
for (int q = j; q < CHUNK_SIZE; q++)
{
// Pre-calculate the array lookup as it is used twice
chunkAccess = i + q * CHUNK_SIZE + k * CHUNK_SIZE_SQUARED;
if (DifferentBlock(chunkAccess, b))
break;
chunkHelper.visitedXN[chunkAccess] = true;
...
}
Garbage Collection (10% speed increase)
Each array in ChunkHelper must be reset to false before being re-used by another chunk. Initially we were re-allocating a new boolean array, however this put excessive pressure on the garbage collector. Array.Clear was a much better solution and quickly resets the array back to false:
// Old
public void Reset()
{
visitedXN = new bool[CHUNK_SIZE_CUBED];
// Same for X+, Y-, Y+, Z- and Z+
...
}
// New
public void Reset()
{
Array.Clear(visitedXN, 0, CHUNK_SIZE_CUBED);
// Same for X+, Y-, Y+, Z- and Z+
...
}
Memory (20% speed increase)
Initially, AppendQuad returned an array of 6 uints, which was then copied to a temporary buffer stored in a ChunkHelper. In the GenerateMesh function we would then check if this buffer has exceeded a certain size and copy it to the vertex buffer. This involved a lot of Array.Copy calls.
Instead, AppendQuad is passed the vertex buffer as a parameter and writes to it directly. This removes a lot of expensive Array.Copy functions, however we need to ensure we do not overflow the vertex buffer:
public void GenerateMesh(...)
{
...
// Extend the array if it is nearly full
if (vertexBuffer.used > vertexBuffer.data.Length - 2048)
vertexBuffer.Extend(2048);
...
}
// Function inside BlockVertexBuffer:
class BlockVertexBuffer
{
...
public void Extend(int amount)
{
uint[] newData = new uint[data.Length + amount];
Array.Copy(data, newData, data.Length);
data = newData;
}
...
}
Block Access (20% speed increase)
Initially, blocks were only accessed in the map class by their global map positions. We reduced our chunk initialisation time by accessing blocks directly within the chunk where possible.
IsNoBlock is still used and has been optimised using bit shifts and bit masks:
public class Map
{
Chunk[,,] chunks;
const byte SHIFT = 5;
const int MASK = 0x1f;
const int MAP_SIZE_X = 512;
const int MAP_SIZE_Y = 160;
const int MAP_SIZE_Z = 512;
// Returns true if there is no block at this global map position
public bool IsNoBlock(int x, int y, int z)
{
// If it is at the edge of the map, return true
if (x < 0 || x >= MAP_SIZE_X ||
y < 0 || y >= MAP_SIZE_Y ||
z < 0 || z >= MAP_SIZE_Z)
return true;
// Chunk accessed quickly using bitwise shifts
var c = chunks[x >> SHIFT, y >> SHIFT, z >> SHIFT];
// To lower memory usage, a chunk is null if it has no blocks
if (c == null)
return true;
// Chunk data accessed quickly using bit masks
return c.data[(x & MASK) + (y & MASK) * CHUNK_SIZE, (z & MASK) * CHUNK_SIZE_SQUARED].kind == EMPTY;
}
}In Practice
This engine was created from scratch for our first person shooter Sector's Edge. We did not use an existing game engine as we desired the ability to fine-tune every aspect of the rendering pipeline. This allows the game to run on older hardware and at rates higher than 60 frames per second.
The full source code for this article is available here on GitHub.
If you have any questions, feel free to reach out to me on our Discord server.
I have also written a breakdown of each stage in the rendering and post-processing pipeline, which is available here.